Who has not heard of Siri?! With Apple's iPhone 4S launch, it enjoyed immense popularity,
only to be mocked a few months later as yet another futuristic AI promise that never quite lived up to its hype.
Yet, it's too easy to dismiss Siri as flop before we appreciate the complexity of the problem.
Natural Language Understanding tackles a daunting task: teaching computers to understand human speech.
Not merely transcribing speech into words – that can be done already - but actually extracting the meaning.
A sound solution to this problem is the holy grail of Artificial Intelligence, and Siri was an important milestone towards that goal,
spawning a new generation of voice assistants. Yet, that “Siri generation” can only support a narrow set of commands and actions,
and now both consumers and businesses are yearning for more. It’s time for the next disruptive cycle. Enter Robin.
Our approach differs fundamentally from the existing techniques.
Today’s industry practices pragmatically narrow down the problem to create highly specialized solutions.
Alas, such solutions do not scale, proving extremely fragile once original assumptions change.
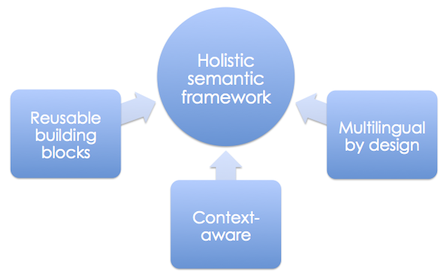
Conversely, we begin with a holistic model of language semantics, a unified methodology with reusable building blocks can be applied to any vertical,
and dramatically speeds up the creation of individual-yet-interconnected assistants.
Unlike Siri, our platform is open, expandable and can be taught new concepts and phrases in a straightforward manner. It's called Robin.AI.
In our framework, an Assistant is simply a combination of one or more Task Agents. In essense, Task Agents are vertical reusable building blocks specializing
on specific tasks. For instance, the Alarm Agent knows how to set alarms and
understands related commmands. The platform offers a collection of ready-to-go Task Agents for a variety of basic tasks such text messaging,
local search, fetching traffic information, etc. In addition, developers can define Task Agents: either from scratch
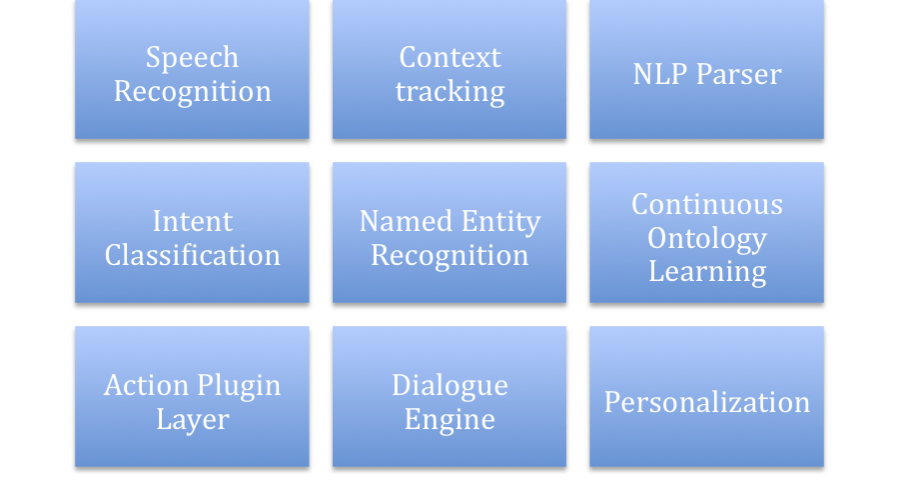
or using other agents ones as building blocks. The platform support agents for the following tasks:
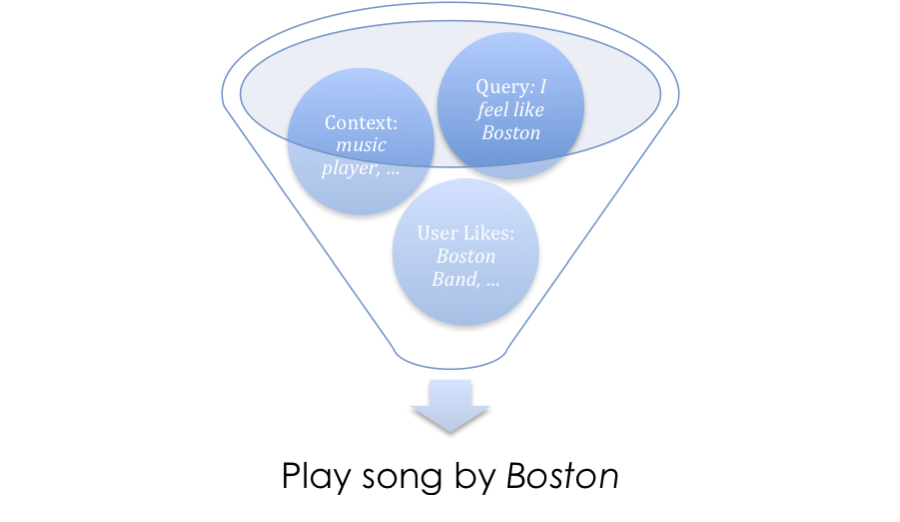
At its core, Robin is essentially a User Intent Recognition Machine, operating based upon three inputs: query phrase, context and the user model:
Intent = Query * Context * User
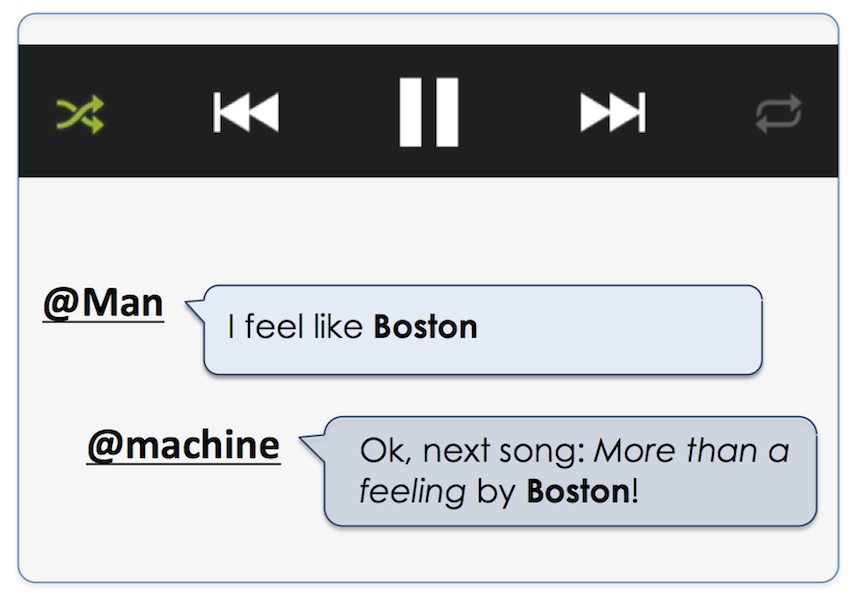
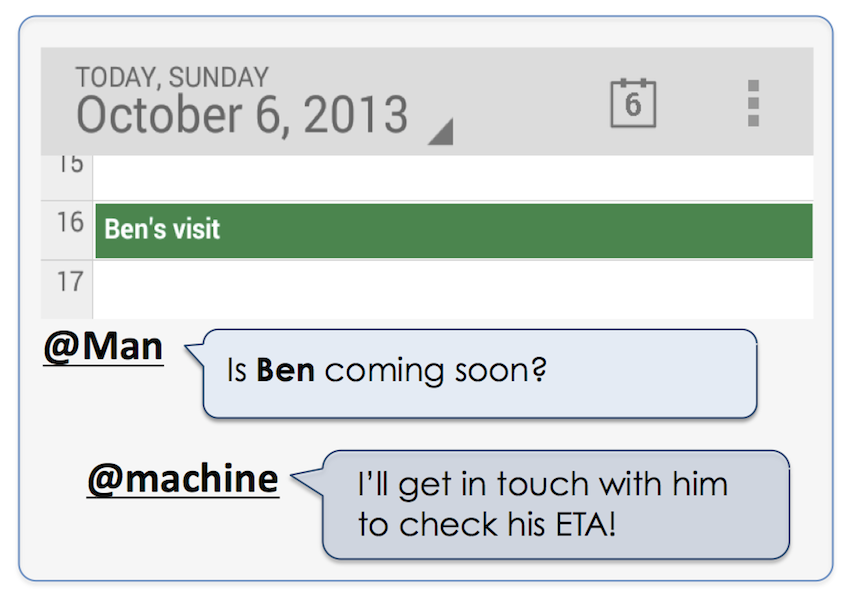
Example: While listening to music, the user feels like hearing a song by Boston (a popular rock band from the 80s that he happens to like a lot).
This query is too ambiguous to determine the user’s intent.
Which Boston? The city? The band? Or perhaps the Boston Deli eatery around the corner? Luckily, the assistant gets to know the user,
including his musical preferences. Likewise, it keeps track of the current device context (music player being active),
and putting these pieces of evidence together allows accurate intent recognition.
Finally, the response is phrased in a way that matches the user’s personal style. Some people want a butler,
while others are looking for a “bro”. It’s personal!
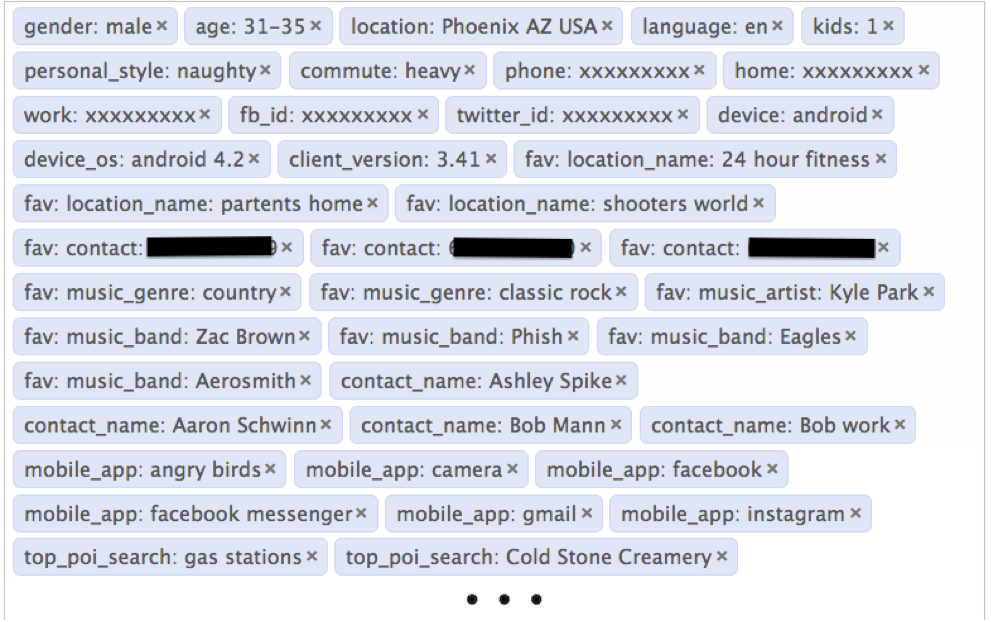
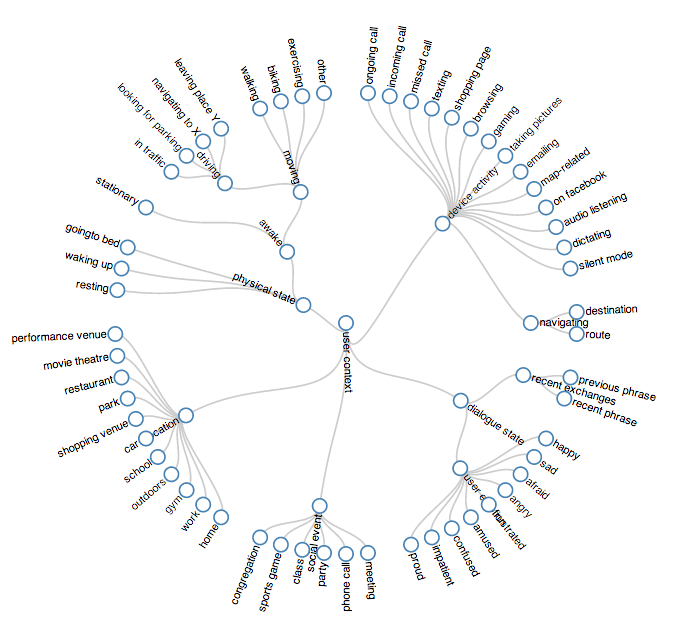
User model and context management is built into every assistant running on Robin.AI. It is a continuous process that requires
the aggregation and tracking of hundreds of variables as shown below.
User context model:
Robin stack comprises the following engines
-
A mobile workforce/task management system called FleetOp wants to add a voice UI for their users to be able to manage
their tasks on the go. Possible queries include: “What’s next on my list?.. Give me directions there!”, “Reassign this task to X”, etc.
With Robin.AI, FleetOp can achieve this task without being an NLP expert or even a programmer!
Since Robin.AI already has a Task Management Agent, the Task concept is already defined, along with typical task attributes such as task owner, priority, deadline, etc. Since FleetOp tasks also possess a geographical context, they require an extra Location attribute, which automatically enables support for route direction and other location-based queries. Additionally, to support references to teams and team members, FleetOp needs to import their respective names into the system and voila: the FleetOp voice assistant is born!
-
Alice wants to create a cooking assistant called Le Chef to teach him recipes and guide her in the kitchen with speech-interactive culinary directions. Le Chef would have to support questions like, “How do I make a Tiramisu?”, “What should the oven temperature be”, etc. Again, Robin.AI comes in handy.
Handling the Tiramisu query involves two tasks: searching (Vertical Search Agent) and then presenting the recipe to the user as a navigable list of instructions (List Navigation Agent). In fact, Alice doesn’t have to be aware of these technicalities: Robin already knows that any search command should trigger a Search Agent and that Recipe ISA list-of (Instructions), engaging a List Navigation as a result.
Selected Publications
-
Boris Galitsky
[hide abstract]
ABSTRACT: We build an open-source toolkit which implements deterministic learning to support search and text classification tasks.
We extend the mechanism of logical generalization towards syntactic parse trees and attempt to detect weak semantic signals from them.
Generalization of syntactic parse tree as a syntactic similarity measure is defined as the set of maximum common sub-trees and performed at a level of paragraphs,
sentences, phrases and individual words. We analyze semantic features of such similarity measure and compare it with semantics of traditional anti-unification of terms.
Nearest-neighbor machine learning is then applied to relate a sentence to a semantic class.
Using syntactic parse tree-based similarity measure instead of bag-of-words and keyword frequency approach, we expect to detect a weak semantic signal otherwise unobservable.
The proposed approach is evaluated in a four distinct domains where a lack of semantic information makes classification of sentences rather difficult.
We describe a toolkit which is a part of Apache Software Foun-dation project OpenNLP, designed to aid search engineers in tasks requiring text relevance assessment.
Engineering Applications of Artificial Intelligence 03/2013; 26(3):1072–1091.
-
[hide abstract]
ABSTRACT: One of the main problems to be solved while assisting inter-human conflict resolution is how to reuse the previous experience with similar agents. A machine learning technique for handling scenarios of interaction between conflicting human agents is proposed. Scenarios are represented by directed graphs with labelled vertices (for communicative actions) and arcs (for temporal and causal relationships between these actions and their parameters). For illustrative purposes, classification of a scenario is computed by comparing partial matching of its graph with graphs of positive and negative examples. Nearest Neighbour learning is followed by the JSM-based learning which minimised the number of false negatives and takes advantage of a more accurate way of matching sequences of communicative actions. Developed scenario representation and comparative analysis techniques are applied to the classification of textual customer complaints. It is shown that analysing the structure of communicative actions without context information is frequently sufficient to estimate complaint validity. Therefore, being domain-independent, proposed machine learning technique is a good compliment to a wide range of customer relation management applications where formal treatment of inter-human interactions is required in a decision-support mode.
J. Exp. Theor. Artif. Intell. 01/2008; 20:277-317.
-
[hide abstract]
ABSTRACT: In this paper, we apply concept learning techniques to solve a number of problems in the customer relationship management (CRM) domain. We present a concept learning technique to tackle common scenarios of interaction between conflicting human agents (such as customers and customer support representatives). Scenarios are represented by directed graphs with labeled vertices (for communicative actions) and arcs (for temporal and causal relationships between these actions and their parameters). The classification of a scenario is performed by comparing a partial matching of its graph with graphs of positive and negative examples. We illustrate machine learning of graph structures using the Nearest Neighbor approach and then proceed to JSM-based concept learning, which minimizes the number of false negatives and takes advantage of a more accurate way of matching sequences of communicative actions. Scenario representation and comparative analysis techniques developed herein are applied to the classification of textual customer complaints as a CRM component. In order to estimate complaint validity, we take advantage of the observation [19] that analyzing the structure of communicative actions without context information is frequently sufficient to judge how humans explain their behavior, in a plausible way or not. This paper demonstrates the superiority of concept learning in tackling human attitudes. Therefore, because human attitudes are domain-independent, the proposed concept learning approach is a good compliment to a wide range of CRM technologies where a formal treatment of inter-human interactions is required.
Information Sciences. 05/2011;
-
[hide abstract]
ABSTRACT: We implement a scalable mechanism to build a taxonomy of entities which improves relevance of search engine in a vertical
domain. Taxonomy construction starts from the seed entities and mines the web for new entities associated with them. To form
these new entities, machine learning of syntactic parse trees (syntactic generalization) is applied to form commonalities
between various search results for existing entities on the web. Taxonomy and syntactic generalization is applied to relevance
improvement in search and text similarity assessment in commercial setting; evaluation results show substantial contribution
of both sources.
Conceptual Structures for Discovering Knowledge - 19th International Conference on Conceptual Structures, ICCS 2011, Derby, UK, July 25-29, 2011. Proceedings; 01/2011
-
Analyzing Microtext, Papers from the 2011 AAAI Workshop, San Francisco, California, USA, August 8, 2011; 01/2011
-
[hide abstract]
ABSTRACT: We define sentence generalization and generalization diagrams as a special sort of conceptual graphs which can be constructed
automatically from syntactic parse trees and support semantic classification task. Similarity measure between syntactic parse
trees is developed as a generalization operation on the lists of sub-trees of these trees. The diagrams are representation
of mapping between the syntactic generalization level and semantic generalization level (anti-unification of logic forms).
Generalization diagrams are intended to be more accurate semantic representation than conventional conceptual graphs for individual
sentences because only syntactic commonalities are represented at semantic level.
07/2010: pages 185-190;
-
Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems: volume 1 - Volume 1; 01/2010
-
Proceedings of the Twenty-Third International Florida Artificial Intelligence Research Society Conference, May 19-21, 2010, Daytona Beach, Florida; 01/2010